复试-交通异常预测项目
问题与挑战
传统模型的不足之处:
- 仅关注静态特征 (如 POI、历史流量),忽略事件间的动态演化交互;
- 未有效处理数据不平衡, 难以捕捉稀有异常事件的内在模式; (最难的一点)
- 空间依赖建模单一, 未考虑多视角 (功能相似、碰撞历史、交通状况) 的网格交互;
- 动态特征演化易出现「过平滑」, 导致正常与异常事件的特征差异被掩盖。
任务的共性挑战:
- 数据不平衡: 异常事件在时空上极度稀疏, 模型易过度拟合正常事件, 难以学习异常模式;
- 静态 - 动态特征的联合建模: 静态特征 (如 POI) 是固定的, 动态特征 (如事件交互) 是时变的, 二者的依赖关系复杂, 需设计灵活的融合机制;
- 多视角空间依赖捕捉: 网格 (也就是某个地区) 间的影响不仅来自地理邻近, 还来自功能相似、碰撞历史关联等, 单一空间图无法全面覆盖; (另类的数据融合问题)
- 动态演化中的过平滑: 动态特征随时间更新时, 易因正常事件的累积导致异常与正常事件的特征趋同, 降低模型区分度;
- 训练效率与时间依赖的平衡: 动态演化具有强时间依赖, 传统批处理会破坏时序关系, 而单样本训练效率极低。
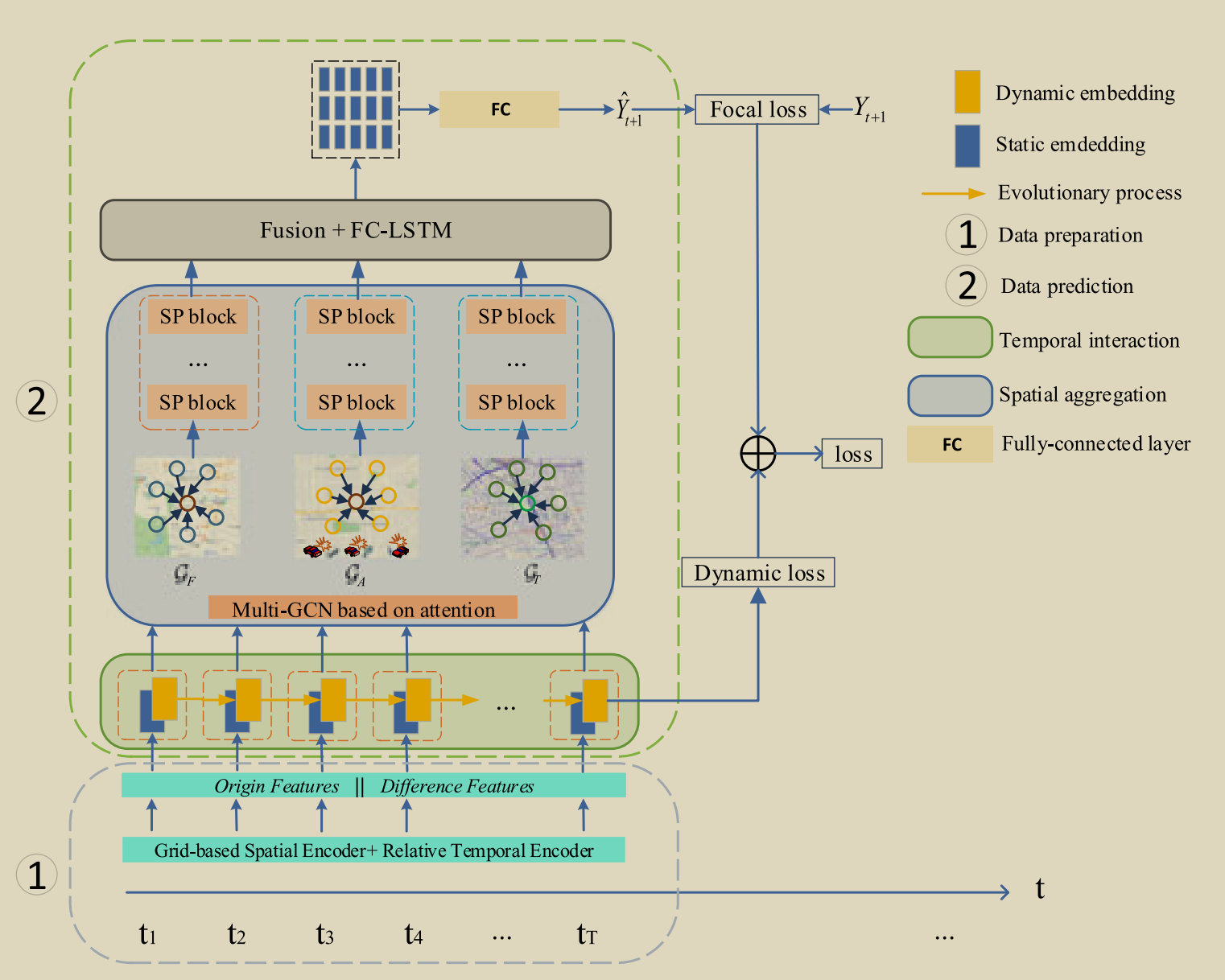
数据集
数据集: 纽约市 (NYC) 和芝加哥 (Chicago) 的真实时空数据集。
数据构成: 时空数据: 城市网格划分: 按经纬度将纽约市 (NYC) 排除公园 / 湖泊等无碰撞区域); 时间切片: 将时间按 1 小时为单位分割 (如 2016-06-01 16:00-17:00 为一个切片) 特征数据: 静态特征: POI (车库、学校、商业区等)、交通设施 (公交站、高速、信号灯)、天气 (降雨 / 积雪 / 温度); 动态特征: 交通流量 (出租车上下车位置 / 时间)、历史碰撞事件; 标签: 每个 “网格 - 时间切片” 的二元标签 (1 = 有碰撞异常, 0 = 无异常)
数据集预处理
数据预处理(3 步):
-
归一化:用 Max-Min 归一化将所有特征(如 POI 数量、交通流量)映射到 [0,1] 区间,避免因特征量级差异(如 POI 数为 “千级”,天气温度为 “十级”)导致模型偏向量级大的特征;
-
特征构造:计算 “差异特征 $D_t$” 对每个网格,用当前时刻的静态特征(如当前交通流量)减去 “过去 5 个正常时刻的特征均值”,公式为:\(D_t^l = O_t^l - \frac{1}{n} \sum_{i=1}^{n} O^l(t_i, \text{nor})\)($O_t^l$ 为网格 l 在 t 时刻的原始特征,n=5 为历史正常样本数);
设计意图:异常事件的特征通常偏离正常状态,能放大这种偏离,帮助模型快速识别异常;
-
数据集划分:按 “时间顺序” 将数据分为训练集(60%)、验证集(20%)、测试集(20%),而非随机划分 —— 避免未来数据泄露到历史数据中(如用 2016 年 12 月数据训练,预测 2015 年数据,不符合真实场景)。
时空信息编码器
空间编码
数学原理
对经度进行以下操作,获得编码向量
\[\begin{aligned} PE(l_{lat}, 2k) &= \sin(\frac{l_{lat}}{10000^{2k/D}}) \\ PE(l_{lat}, 2k + 1) &= \cos(\frac{l_{lat}}{10000^{2k/D}}) \end{aligned} \quad k = 0, 1, ..., \frac{D}{2} - 1\]同理,对纬度也进行如下操作
\[\begin{aligned} PE(l_{lon}, 2k) &= \sin(\frac{l_{lon}}{10000^{2k/D}}) \\ PE(l_{lon}, 2k + 1) &= \cos(\frac{l_{lon}}{10000^{2k/D}}) \end{aligned} \quad k = 0, 1, ..., \frac{D}{2} - 1\]Q1:为什么要对位置信息进行编码操作?
A1:为了解决非线性,非周期,破坏语义信息三个问题
- 非线性:经纬度和地理位置的对应关系并非线性表示
- 非周期:空间邻近性的断裂,比如179.9和0
- 破坏语义信息:都是首都,但是简单的经纬度并不能体现这一点(查的距离很远,但是特点可能相似,这时候需要我们用低频的角度去看)
Q2:为什么要对奇偶不同的k进行正余弦变换
A2:因为$PE_k(x) = \sin(\omega_k x)$是有歧义的,因为$\sin(x) = \sin(\pi - x)$所以不同位置可能编码一样,比如函数值1/2对应了30度和150度,但是分为$(\sin(\omega x), \cos(\omega x))$,则可以表示单位圆上的一个点
Q3:这个k是什么?
A3:表示频率的敏感度,高频的话就对一些细微的差距很敏感,可以用于识别小范围的变化(比如下个十字路口和这个十字路口的区别)。低频则是对更宏观的变化的识别(比如跨城市)
时间编码
输入:当前时间 $t$ 与历史事件起始时间 $t_1$ 的时间差(而非绝对时间,如“距离上次碰撞已过去 3 小时”);
编码逻辑:用指数衰减函数编码时间差,公式为:$ZE(t, 2k) = \sin((t - t_1)/10000^{2k/D})$
\[ZE(t, 2k + 1) = \cos((t - t_1)/10000^{2k/D})\]最终得到时间编码向量 $ZE(t) \in \mathbb{R}^{2D}$;
Q:为什么用相对时间?而非绝对时间,每天的绝对时间没有特征么?比如早晚高峰时间?
绝对思维太笨了,想对思维更灵活 风险是“事件驱动”,且随时间间隔衰减,比如某一时刻高速路上发生了车祸,后面发生车祸的概率也会增大,比如追尾
静态嵌入(这个地方本来就危险不危险?)
- 输入特征: 原始静态特征$O_t \in \mathbb{R}^{N \times D}$ (N 为网格数, D 为特征维度, 如 POI、天气)、差异特征$D_t \in \mathbb{R}^{N \times D}$ (当前与历史正常的偏差);
\(D_{t}^{l} = O_{t}^{l} - \frac{1}{n}\sum_{i=1}^{n}{O^{l}}_{(t_{i}, nor)}\) 这里的n取5,nor表示要挑数据中的正常状态的特征,应该是按例此刻最近的五个正常的时间
- 特征融合: 将$O_t$与$D_t$拼接, 得到“静态特征基础向量”$O_t \oplus D_t \in \mathbb{R}^{N \times 2D}$ ($\oplus$表示拼接);
这里就是单纯的把两个向量拼在一起了
- 加入时空编码: 将“静态特征基础向量”与“空间编码$PE$”“时间编码$ZE$”再次拼接, 得到最终静态嵌入$X_t^s \in \mathbb{R}^{N \times 2D}$ (注: 此处维度仍为 2D, 因$PE$和$ZE$的信息已通过融合融入, 实际计算中会调整维度匹配);
这里的维度不匹配的情况就体现了融合,比如2048到1024 ——两个格子取平均塞进去,如果1024到2048,那就把一个格子平分成两份
$X_t^s$是一个N行2D列的矩阵,行代表网格,D代表特征,所以每一行就是代表某个网格里面的
静态特征(不全是静态,是由原始静态特征$O$,动态的差异特征$D_t$,动态的时空编码$PE+ZE$共同组成的“综合环境状态”),举个例子 \(X_t^s = \begin{bmatrix} \text{网格1的特征向量} \\ \text{网格2的特征向量} \\ \vdots \\ \text{网格1000的特征向量} \end{bmatrix} = \begin{bmatrix} 0.12 & -0.56 & 0.03 & \dots & 0.99 \\ -1.20 & 0.45 & 0.88 & \dots & -0.01 \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0.05 & 0.11 & -0.32 & \dots & 0.77 \end{bmatrix}_{1000 \times 128}\)
创新点:在融合的时候引入深度学习模型!
动态演化嵌入(解决数据不平衡和动态特征过平滑的问题)
通过“Update-Decay”机制,解决数据不平衡和动态特征过平滑的问题。 目的:记住稀有异常,遗忘冗余正常,保留事件的演化规律
不平衡:静态数据过多 过平滑:信息太多,导致好不容易来个动态的特征,也无法激起什么波动
创新点:
加入自适应平滑门
解释: 时间序列:[11, 13, 9, 13, 15, …] ← 有噪声抖动!(变化一般不会这么急剧,可能是传感器异常) 真实情况: [11, 13, 11, 13, 15, …] ← 应该更平滑
让动态特征更加稳定可靠, 增强鲁棒性 (泛化能力/通用性)。
具体操作
- 动态嵌入初始状态
训练开始时,所有网格的动态嵌入\(X_{t=0}^d \in \mathbb{R}^{N \times 2D}\)初始化为 0 向量 —— 表示“无历史事件记忆”。
空白向量会和流量等动态特征相加。
- Update 操作(触发条件:网格 $l$ 在 $t$ 时刻有碰撞异常,标签 $y=1$)
计算逻辑:\(X_{(t,l)}^d = \sigma(X_{(t,l)}^s \cdot W_1 + X_{(t-1,l)}^d \cdot W_2)\)
其中:$\sigma$ 为 sigmoid 激活函数(控制输出在 $[0,1]$),$W_1 \in \mathbb{R}^{2D \times 2D}$、$W_2 \in \mathbb{R}^{2D \times 2D}$ 为可训练权重矩阵;
如果出事了,这个动态特征就会记住这个“创伤” 可训练矩阵的意思是,这个参数是会变化的,通过反向传播来改变
- Decay 操作(触发条件:网格 $l$ 在 $t$ 时刻无异常,标签 $y=0$)
计算逻辑:\(X_{(t,l)}^d = X_{(t-1,l)}^d \cdot e^{-\phi \cdot (t-t_0)}\)
对可能出事的路口(创伤)的遗忘过程
其中:$\phi$ 为衰减常数(论文设为 2),$t_0$ 为网格 $l$ 上一次发生异常的时间;
问题
-
为什么更新过程有静态特征,而衰减过程没有静态特征?
- 静态特征是“风险的基础盘”,不同网格面对相同动态变化表现形式应该是不一样的(无人的道路撞车的影响和闹市区撞车的影响不同,后者可能会导致堵车很长时间)
-
为什么衰减的时候没有静态特征
- 遗忘冗余正常,还可以保留事件的时间演化规律
- 没有新事故,环境特征就不再起作用了,剩下的只是记忆随时间的自然衰减,环境(静态特征)只负责“制造”风险,而不负责“维持”风险(如果老师按照1的思路拷打你,既然不同网格对动态变化的反应不一样,那衰减不应该也不一样吗?回答就是:尝试加入静态特征,但是效果不如不加好,因为会导致动态特征过平滑)
- Decay的目标是遗忘,如果加上了静态特征的话,你要多久才能遗忘干净呢
-
如何处理正常数据的?(如何平衡正常和异常数据的?/如何淡化正常数据的影响?/如何解决数据类型不平衡问题?)
- 强调Decay设计,通过Update-Decay共同协调
空间相互影响表示学习
注意力机制多图卷积(Multi-GCN with Attention)(同样为了防止过平滑)
传统的图卷积(GCN)往往是“一视同仁”地取平均值(大家都听),而这里引入注意力机制(Attention)就是为了“偏心”——谁跟我像,谁跟我关系铁,我就多听谁的。
为每个空间图设计“空间注意力块(SP 块)”,学习邻居网格的“贡献权重”(避免平等对待所有邻居),具体流程:
-
输入:静态嵌入序列 \(X_s = [X_{t-T+1}^s, ..., X_t^s] \in \mathbb{R}^{T \times N \times 2D}\) (T=5 为历史时间切片数)、动态嵌入序列 \(X_d = [X_{t-T+1}^d, ..., X_t^d] \in \mathbb{R}^{T \times N \times 2D}\);
-
注意力权重计算 (以动态嵌入$X_d$为例,其实静态特征也要这样过一遍):
-
定义 Query (查询)、Key (键)、Value (值):
- \[Q_d = X_d \cdot W_{dq}\]
- \[K_d = X_d^{(k+1)} \cdot W_{dk}\]
- $V_d = K_d$ (值与键来源一致,简化计算)
Q1:为什么K和V设计能一致(邻居动态键和动态值设置的相等,但是不怎么影响效果?)两个都可以直接拿数值表示。
注意,V和K通常是不一样的,K表示表情,V表示内容,但有可能K和V表达的意思比较相近,比如一本书的封面可以判断一本书的大概内容,但是有可能书就只有一页封面,那么内容不就和封面一样了,也就是可以看作V=K
(\(W_{dq} \in \mathbb{R}^{2D \times 2D}\)为权重矩阵),权重,一个学习的人,可以变化的矩阵 ($X_d^{(k+1)}$为邻居网格的动态嵌入,\(W_{dk} \in \mathbb{R}^{2D \times 2D}\))
- 计算注意力权重 (Softmax 归一化):$A_d = \text{Softmax}(\frac{Q_d \cdot K_d^T}{\sqrt{2D}}) \in \mathbb{R}^{T \times N \times 1 \times (k+1)}$ ($\sqrt{2D}$为缩放因子,避免权重过大)
- 邻居特征聚合:$X_d’ = A_d \cdot V_d \in \mathbb{R}^{T \times N \times 2D}$ (将邻居特征按权重加权求和)
Q:为什么两个地方越像,注意力越大?
这句话是错的,因为取决于你对数据的训练方式!在本次任务中,两个地方的特点越近似,我们就越需要注意!
仅仅从向量角度来说
我们在计算注意力时用的是 点积(Dot Product):$Q \cdot K^T$ 从几何数学上讲:
- 方向一致(相似): 当两个向量指向同一个方向,它们的点积最大。
- 方向垂直(无关): 点积为 0。
- 方向相反(差异): 点积为负。
-
静态嵌入$X_s$执行相同操作, 得到$X_s’$;
-
残差连接: 为避免梯度消失, 将聚合后的特征与原始特征相加, 公式为: \(X_f^1 = X_s' \cdot W_s + X_d' \cdot W_d + [X_s; X_d]\)
上角标代表这是第几次加工 \((W_s, W_d \in \mathbb{R}^{2D \times 2D} \text{为权重}, [X_s; X_d] \text{为原始特征拼接})\)
通过注意力机制,模型能自动判断 “哪个邻居对当前网格的风险影响更大”(如某邻居近期频繁异常,其权重更高)。
为每个城市构建 3 个无向图, $G = (V,A)$ ($V$ 为网格节点, $A$ 为邻接矩阵) 为邻接矩阵), 分别对应不同关联维度。
功能相似图 $G_F$: 基于 POI 分布相似度 (如 “均为商业区” 的网格更相关)
碰撞关联图 $G_A$: 基于历史碰撞记录相似度 (如 “碰撞次数、伤亡情况相似” 的网格更相关)
交通状况图 $G_T$: 基于交通设施分布相似度 (如 “均为高速密集区” 的网格更相关)
多图联合学习
将三类图 $(G_F, G_A, G_T)$ 的 SP 块输出特征投影到统一空间, 公式为:
\[\hat{X}_f = X_f^F \cdot W_{GF} + X_f^A \cdot W_{GA} + X_f^T \cdot W_{GT}\]其中: $X_f^F, X_f^A, X_f^T$ 分别为三类图的 SP 块输出, \(W_{GF}, W_{GA}, W_{GT} \in \mathbb{R}^{4D}\) 为可训练权重 (反映每类图的贡献度) ;通过学习权重可以让模型知道“哪类空间关联对预测更重要”
Q:这里的Xf Xa Xt都是怎么得到的?
-
模型在计算注意力 $A_d$ 时,只看那些“POI 功能相似”的邻居(比如找其他商业区)。
-
然后套用残差公式:$X_f^F = \text{Attention}(G_F) \dots + [X_s; X_d]$。
Q:4D是怎么来的
注意到 $W \in \mathbb{R}^{4D}$。
还记得上一张图里的残差连接公式吗?
\[X_f^1 = \dots + [X_s; X_d]\]这里有一个 $[X_s; X_d]$ 的拼接操作。
-
$X_s$ 是 $2D$ 维。
-
$X_d$ 是 $2D$ 维。
-
拼在一起就是 $4D$ 维。
特征融合与预测
整合“时空演化特征”和“空间关联特征”,通过时序建模输出每个网格的异常概率。具体操作(两步):
- FC-LSTM 层(捕捉时空依赖):
输入:多图联合特征$\hat{X}_f \in \mathbb{R}^{T \times N \times 4D}$(T=5 为时间切片数,N为网格块数,4D 为特征维度);
作用:同时建模“时间维度的演化”(LSTM 层)和“特征维度的关联”(FC 层):
FC 层:将每个网格的 4D 特征映射为非线性表示,捕捉“静态 - 动态特征的交互”(如“雨天 + 近期异常”的组合风险);理解为加了个激活函数
LSTM 层:处理 T 个时间切片的特征,捕捉“时间序列依赖”(如“连续 2 小时流量异常→下 1 小时碰撞风险高”);
输出:LSTM 的隐藏状态$H_t \in \mathbb{R}^{N \times 4D}$(包含 N 个网格的时空融合特征)。
- 全连接层:(前馈神经网络)
输入:LSTM 隐藏状态$H_t$;
计算逻辑:通过全连接层 + Sigmoid 激活函数,将特征映射为 [0,1] 区间的概率:\(\hat{Y}_{t+1} = \sigma(H_t \cdot W_3 + b)\)
其中:$W_3 \in \mathbb{R}^{4D \times 1}$为权重矩阵,b 为偏置,\(\hat{Y}_{t+1} \in \mathbb{R}^N\)为每个网格的“下一时间切片异常概率”;
损失函数
根据目的的不同,设置不同的损失函数。
模型训练的“优化目标”:同时解决 数据不平衡(异常样本少); 动态特征过平滑。
损失函数设计成了两部分,第一部分是利用交叉熵解决数据不平衡,第二部分是动态损失函数,通过让变换更加突出,解决数据过平滑的问题
1.改进 Focal Loss(解决数据不平衡)仅通过“难度权重”关注难分类样本,未考虑动态特征的演化;
\[L_F = -\alpha \cdot (1 - \hat{Y})^\gamma \cdot Y \cdot \log(\hat{Y}) - (1 - \alpha) \cdot \hat{Y}^\gamma \cdot (1 - Y) \cdot \log(1 - \hat{Y})\]见到log条件反射般的想到交叉熵(解决数据不平衡,学着学着趋同的情况,增加熵,保持分离度)
其中:$\alpha = 0.25$(平衡正负样本权重),$\gamma = 2$(放大难分类样本的损失),$\epsilon = 0.9$(对预测概率 > 0.9 的易分类样本,损失衰减);
2.动态损失(解决过平滑)
| 计算逻辑:仅在 Update 操作(y=1)时生效,公式为:$$L_D = \max(0, a - | X_{(t,l)}^d - X_{(t-1,l)}^d | )$$ |
其中:a=6 为阈值(论文实验确定);
3.最终损失函数
将两种损失加权融合,公式为:$L = L_F + \lambda \cdot L_D$
模型训练与优化
- 采用按时间顺序批处理训练策略,不采用随机处理以防破坏时序。
- 优化器采用Adam(自适应学习率,(觉得太慢了就自己调大),适合大规模时空数据)。
- 采取早停策略,验证集性能连续 5 个 epoch 不提升则停止(模拟卷写了几张发现分数提不上来了,可以直接去考试了),降低训练开销并防止过拟合训练。
- 最终输出:每个城市网格在“下一个时间切片”(如 1 小时后)的异常概率,预测判断:概率 > 0.5 → 预测为“异常”(需预警),否则为“正常”。
Q&A
为什么两个地方越像,注意力越大?
这个结论仅是对本项目适用,所以这句话是错的,因为取决于你对数据的训练方式!
- 相似性是由“可学习的矩阵”定义的
在本项目中,计算注意力的 Q(查询)和 K(键)并不是原始数据,而是经过了线性变换:
• Qd=Xd⋅Wdq
• Kd=Xd(k+1)⋅Wdk
这里的 W 被来源描述为“一个学习的人,可以变化的矩阵”。
• 你的理解正确之处: 在几何上,点积 Q⋅KT 确实在向量方向一致时最大。但是,方向是否一致是由 W 决定的。
• 本项目的体现: 通过反向传播,模型会不断调整 W 的数值。如果训练数据告诉模型“某个看似不相关的邻居对预测碰撞更有帮助”,W 就会演化成能将这两个特征映射到同一方向的形态,从而产生高注意力。
- 训练目标:从“物理相似”转向“风险相关”
本项目的组合损失函数 L=LF+λ⋅LD 强制改变了模型“分配注意力”的逻辑,:
• 打破“过平滑”: 传统的训练方式容易让所有地块特征趋同(越学越像),导致注意力失去分辨力,。
• 动态损失 (LD) 的干预: 该损失函数专门用于“让变换更加突出”。它强迫模型在 Update 过程中,必须捕捉到那些即使在原始数据上变化细微、但在风险层面极其重要的动态波动,。
• 结果: 最终模型学习到的“相似”,不再是地理位置或 POI 数量的单纯接近,而是“风险演化规律的相似”。
- 多视角图的权重分配
本项目构建了三类图(功能相似图 GF、碰撞关联图 GA、交通状况图 GT),每类图都有自己的权重矩阵,。
• 训练的导向性: 实验证明,GA(基于历史碰撞记录)的贡献最大。
• 理解: 即使两个地方在功能(GF)上极度相似(比如都是公园),但如果训练过程中发现公园的碰撞特征对预测没有帮助,模型就会通过调整权重 WGF,降低这部分“相似度”在最终决策中的注意力占比
为什么更新过程有静态特征,而衰减过程没有静态特征?
- 静态特征是“风险的基础盘”,不同网格面对相同动态变化表现形式应该是不一样的(无人的道路撞车的影响和闹市区撞车的影响不同,后者可能会导致堵车很长时间)
为什么衰减的时候没有静态特征
- 遗忘冗余正常,还可以保留事件的时间演化规律
- 没有新事故,环境特征就不再起作用了,剩下的只是记忆随时间的自然衰减,环境(静态特征)只负责“制造”风险,而不负责“维持”风险(如果老师按照1的思路拷打你,既然不同网格对动态变化的反应不一样,那衰减不应该也不一样吗?回答就是:尝试加入静态特征,但是效果不如不加好,因为会导致动态特征过平滑)
- Decay的目标是遗忘,如果加上了静态特征的话,你要多久才能遗忘干净呢
如何处理正常数据的?(如何平衡正常和异常数据的?/如何淡化正常数据的影响?/如何解决数据类型不平衡问题?)
- 强调Decay设计,通过Update-Decay共同协调