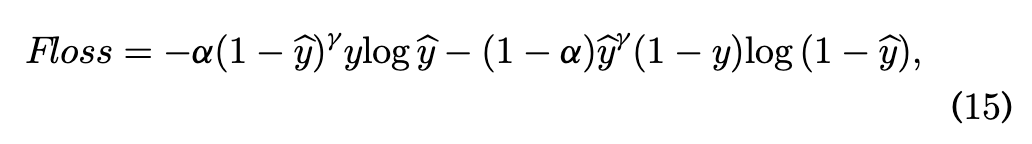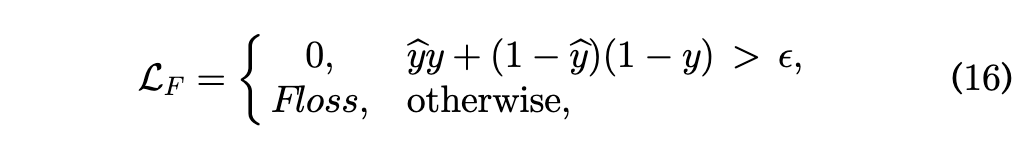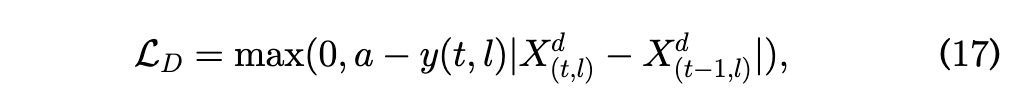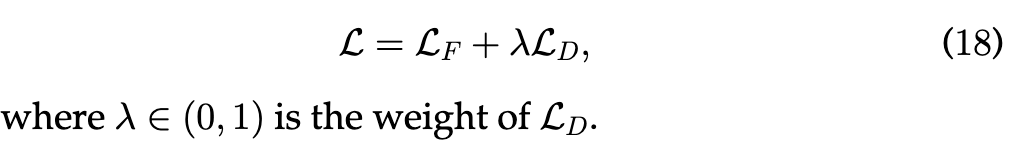交通预测公式笔记
全部公式及其流程
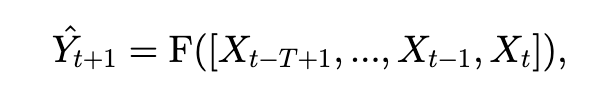
Part1 时空编码

Q1:为什么要对位置信息进行编码操作?
A1:为了解决非线性,非周期,破坏语义信息三个问题
- 非线性:经纬度和地理位置的对应关系并非线性表示
- 非周期:空间邻近性的断裂,比如179.9和0
- 破坏语义信息:都是首都,但是简单的经纬度并不能体现这一点(查的距离很远,但是特点可能相似,这时候需要我们用低频的角度去看)
Q2:为什么要对奇偶不同的k进行正余弦变换
A2:因为$PE_k(x) = \sin(\omega_k x)$是有歧义的,因为$\sin(x) = \sin(\pi - x)$所以不同位置可能编码一样,比如函数值1/2对应了30度和150度,但是分为$(\sin(\omega x), \cos(\omega x))$,则可以表示单位圆上的一个点
Q3:这个k是什么?
A3:表示频率的敏感度,高频的话就对一些细微的差距很敏感,可以用于识别小范围的变化(比如下个十字路口和这个十字路口的区别)。低频则是对更宏观的变化的识别(比如跨城市)

ZE(t) 是一个由不同频率的正弦 ($\sin$) 和余弦 ($\cos$) 函数组成的向量。这里的下标 $1, \dots, k, \dots, D$ 代表不同的频段,注意!这里的D是人为设定的纬度,可能和数据集中的D不一样
点积(Dot Product)对应位置相乘,然后把结果加起来”
所以上面的式子的结果为
\[\cos(t+\delta)\cos(t) + \sin(t+\delta)\sin(t)= \cos((t+\delta) - t) = \cos(\delta)\]Q:为什么用相对时间?而非绝对时间,每天的绝对时间没有特征么?比如早晚高峰时间?
绝对思维太笨了,想对思维更灵活;风险是“事件驱动”,且随时间间隔衰减,比如某一时刻高速路上发生了车祸,后面发生车祸的概率也会增大,比如追尾
Part2 静态嵌入
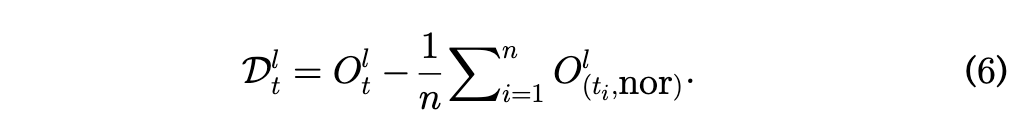
差异特征,表示当前状态与“常态”$O_t^l$的偏离程度,后面减去的nor的含义是,取最近的五个正常时间,nor表示正常标签
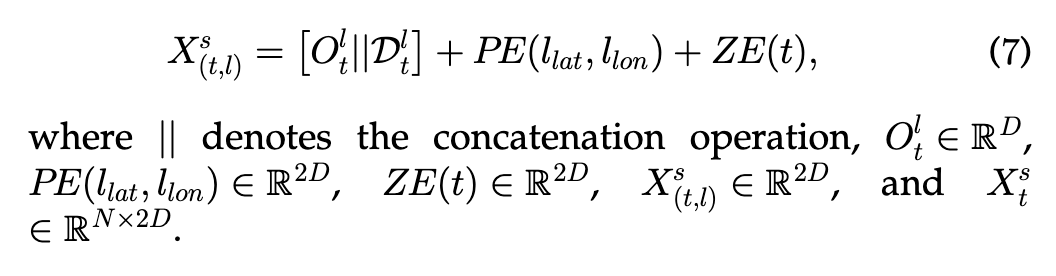
在t时间,第l个网格的静态特征构建表达式,注意这里可能要经过融合操作,因为$O$
和$D$都是纬度为D的向量,拼在一起变成2D
Part3 动态演化过程
最开始所有的网格动态嵌入是要初始化为0的,\(X_{t=0}^d \in \mathbb{R}^{N \times 2D}\)
update-decay机制,如果该时刻无异常,就decay更新,有异常就update更新。
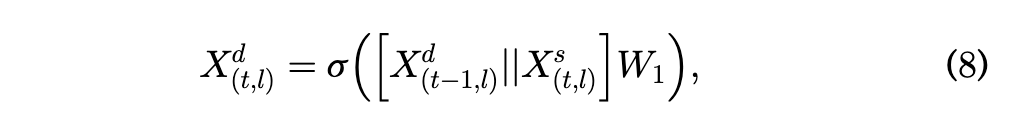
\(X_{t=0}^d \in \mathbb{R}^{N \times 2D}\),上述的$W_1 \in \mathbb{R}^{4D \times 2D}$
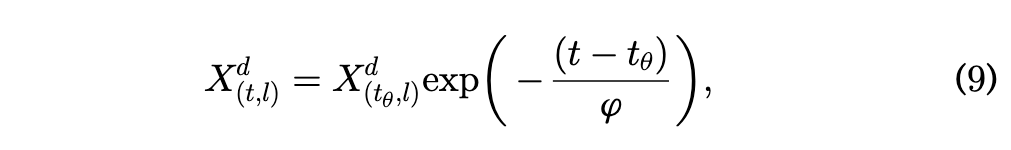
- Update 操作(触发条件:网格 $l$ 在 $t$ 时刻有碰撞异常,标签 $y=1$ ) ,这里略微和论文有点不同,论文上的方法是利用一个大矩阵,可以减少一些时间,但是本质是一样的,如下
计算逻辑:\(X_{(t,l)}^d = \sigma(X_{(t,l)}^s \cdot W_1 + X_{(t-1,l)}^d \cdot W_2)\)
其中:$\sigma$ 为 sigmoid 激活函数(控制输出在 $[0,1]$),$W_1 \in \mathbb{R}^{2D \times 2D}$、$W_2 \in \mathbb{R}^{2D \times 2D}$ 为可训练权重矩阵;
如果出事了,这个动态特征就会记住这个“创伤” 可训练矩阵的意思是,这个参数是会变化的,通过反向传播来改变
- Decay 操作(触发条件:网格 $l$ 在 $t$ 时刻无异常,标签 $y=0$ )
计算逻辑:\(X_{(t,l)}^d = X_{(t-1,l)}^d \cdot e^{-\phi \cdot (t-t_0)}\)
这里的公式和论文上略有一些不同,但是论文上的是此刻的值由$t_\theta$时刻的值来更新。但上述公式是此刻的值由上一时刻更新。即,论文中给出的是通项公式,但是代码里面是递推式。这里应该是数学公式和代码推导式子的差异。
Part4 多空间图构建过程
物理上挨得近并不代表关系密切,我们要找“功能”上相似的“邻居”,为了让模型学到更好的空间关系,构建了三张不同的图(Graph):
将地点分为如下三种
- $\mathcal{G}_F$(Functionality - 功能图): 基于 POI(兴趣点)。比如,“两个地方周围都有很多餐馆和电影院”,那它们在功能上是相似的(都是商业区),即使它们物理距离很远。
- $\mathcal{G}_A$(Collision - 事故图): 基于历史事故记录。比如,“这两个路口都经常发生追尾”,那它们也是相似的。
- $\mathcal{G}_T$(Traffic - 交通设施图): 基于道路设施(公交站台或者道路类型)。
建图过程
- 向量化: 把每个地点的 POI 分布变成一个向量。
- 归一化: 使用 Max-Min Normalization 把数值缩放到一定范围。
- 算距离: 计算两个地点向量之间的欧几里得距离(Euclidean distance)。
- 选邻居 (Top-k): 对于每一个地点,只选跟它最相似的前$k$个地点作为邻居。
以下是邻接矩阵构建式
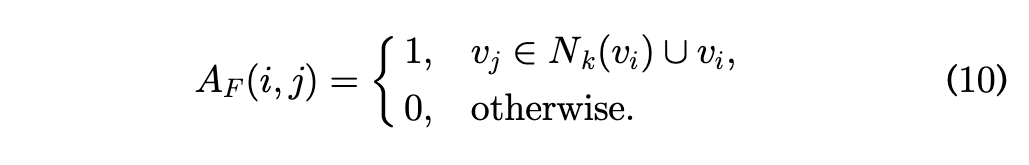
- 如果地点 $j$ 是地点 $i$ 的“前 $k$ 个最相似的朋友”之一(或者 $j$ 就是 $i$ 自己),那么它们之间连一条线(值为 1)。
- 否则,没有连接(值为 0)。
Part5 注意力机制多图卷积(Multi-GCN with Attention)
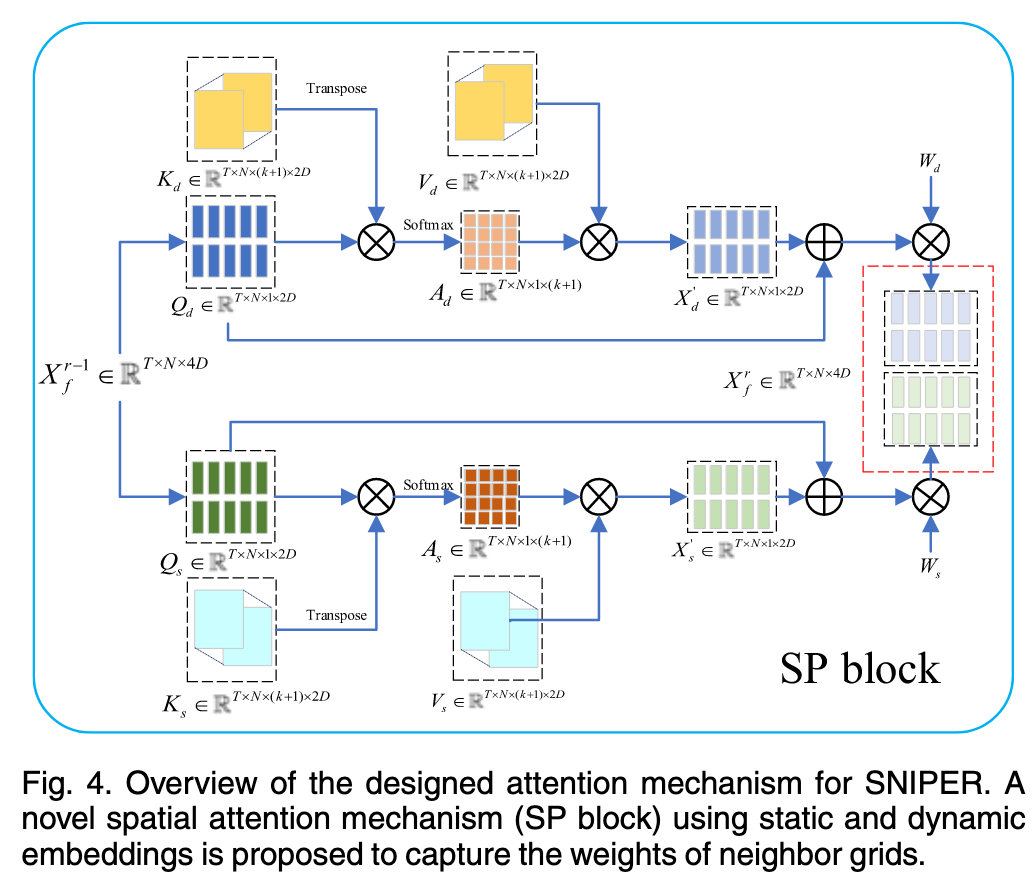

先形成Xs和Xd嵌入,对于每一个X,$\text{Shape} = (T \times N \times 2D)$,T为时间步长N为网格数(T=5 为历史时间切片数),2D是之前设置的特征纬度
通过注意力机制生成权重矩阵(谁和自己像)
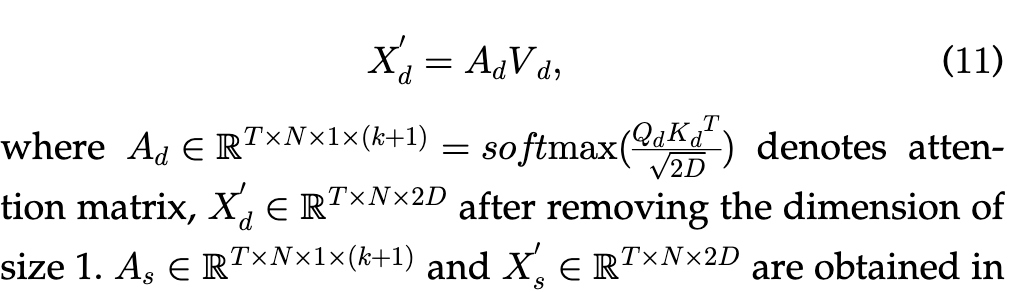
- \(Q_d = X_d W_{dq}\) 代表“中心节点”。它拿着自己的特征去询问周围的邻居:“你们谁跟现在的我最像/最相关?
- \(K_d = X_d^{(k+1)} W_{dk}\) 代表“环境上下文”。它们展示自己的特征,供中心节点 $Q$ 来计算匹配度(点积)
- $V_d = K_d$ (值与键来源一致,简化计算)
\[A_d = \text{Softmax}(\frac{Q_d \cdot K_d^T}{\sqrt{2D}}) \in \mathbb{R}^{T \times N \times 1 \times (k+1)}\]Q1:为什么K和V设计能一致(邻居动态键和动态值设置的相等,但是不怎么影响效果?)两个都可以直接拿数值表示。
注意,V和K通常是不一样的,K表示表情,V表示内容,但有可能K和V表达的意思比较相近,比如一本书的封面可以判断一本书的大概内容,但是有可能书就只有一页封面,那么内容不就和封面一样了,也就是可以看作V=K
Q2:为什么两个地方越像,注意力越大?
这句话是错的,因为取决于你对数据的训练方式!在本次任务中,两个地方的特点越近似,我们就越需要注意!
注意力权重矩阵点积特征,得到xxx(不知道这个词的术语是什么,领据特征权重聚合矩阵?)
\[X_d' = A_d \cdot V_d \in \mathbb{R}^{T \times N \times 2D}\]邻居特征聚合的动态嵌入(即利用注意力机制生成了一个权重矩阵$A_d$,就是谁和自己像,谁的权重就高,最后得到的就是xxx(领据特征权重聚合矩阵?)$X_d’$了)
残差链接
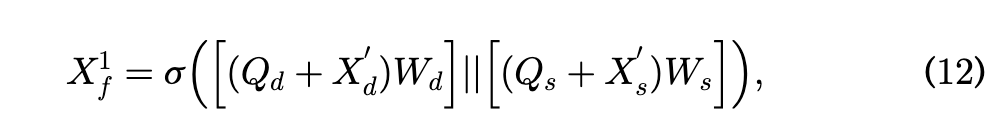
-
残差连接:\((Q_{d} + X_{d}^{\prime})\)
- $Q_d$:当前节点自己的特征。
- $X_d’$:聚合来的邻居特征。
- 这一步把“自己”和“邻居”融合在了一起。
-
特征变换
- 把上一步相加的结果,作为一个整体,乘以权重矩阵 \(w_{ds}\)
注意上面$X$的上角标1,这代表着第1轮SP Block机制得到的结果,再次回顾一下整个SP Block的构建流程,这时候会发现上一次的输出可以用于下一层的输入,本质上是一个多轮迭代邻居的过程.比如,第一轮当前块Cur只能吸收到起邻居B的特征并与其聚合,同时!B也会吸收其邻居C并与其聚合,这时候的B就也有了C的信息.在第二轮的时候A再次吸收B的信息,注意这时候B里面就又有了C的信息,所以第二轮聚合的时候,Cur实际上也有C的信息了,Gemini给出的更严谨解释如下
并行更新 (Parallel Update): 在每一层 $r$ 中,图中的所有节点(如 Cur, B, C)同时聚合其直接邻居的信息。
信息传递 (Message Passing):
- 在 Layer 1,$B$ 聚合了 $C$ 的原始特征,生成了包含一阶邻居信息的表征 $B^{(1)}$。此时 $\text{Cur}$ 仅聚合了 $B$ 的原始特征。
- 在 Layer 2,$\text{Cur}$ 再次聚合 $B$,但此时输入的是更新后的 $B^{(1)}$(其中已隐含 $C$ 的信息)。
感受野扩张 (Receptive Field Expansion): 通过这种方式,经过 $r$ 轮迭代,$\text{Cur}$ 能够有效地捕获距离为 $r$-hops 的高阶邻居(如 $C$)的空间依赖关系,实现从局部到全局的特征融合。
###
GNN 的感受野扩展机制
基于多图卷积网络(Multi-GCN)的联合表征学习
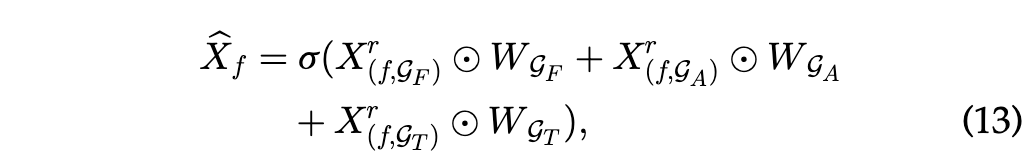
这一步是对不同的视角下的SP Block进行加权求和再激活的过程.
\(X_{(f,{\mathcal{G}_{f}})}^r\)是表示 在「功能相似图」的纬度 $\mathcal{G}_F$ 上,经过 r 轮 SP block 后得到的特征
$\odot$表示哈达玛积,也就是简单的对应位置的元素相乘的操作,这是在学习来自哪张图的预测信息对最终预测更重要
SNIPER模型

Q:这里的r表示SP块的个数,但是之前在上面计算的时候,r不是代表SP Block的迭代轮次吗?
在这里,“SP Block 的个数” 和 “迭代轮次” 指的是同一件事,只是从不同的角度去描述。
当我们说“$r$ 是 SP Block 的个数”时,是在描述模型的架构深度。
- 就像搭积木: 模型在构建时,物理上实例化了 $r$ 个 SP Block 模块,像汉堡包一样一层层叠起来。
当我们说“$r$ 代表邻居聚合的轮次”时,是在描述数据的流动过程。
- 数据流向: 数据必须先流过第 1 个块,处理完的结果变成第 2 个块的输入,以此类推。
- 代码视角: 这是前向传播过程(
forward)。

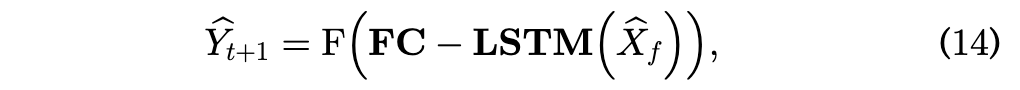
- 降维 (FC): 你的 $\hat{X}_f$ 是 $4D$ 维的,太大了。先通过一个全连接层(Fully Connected)把它压扁一点,提取最精华的信息。
- 时序分析 (LSTM): 把压扁后的序列喂给 LSTM,让它从 $t-T$ 时刻一直看到 $t$ 时刻。
- 预测: 拿出 LSTM 在最后时刻吐出来的那个向量,映射成 0~1 的概率。